Jeder redet über KI. ChatGPT, Claude, Gemini, überall. Aber wenn du mal ehrlich bist: Weißt du eigentlich, was da drin passiert?
Die meisten Leute nutzen diese Tools jeden Tag, ohne zu verstehen, wie sie funktionieren. Das ist in Ordnung. Du musst auch nicht verstehen, wie ein Motor funktioniert, um Auto zu fahren. Aber wenn du weißt, wie eine KI denkt, wirst du sie auch viel besser nutzen können.
Also, lass uns das mal angehen. Kein Fachchinesisch, kein akademisches Kauderwelsch. Einfach erklärt, so wie ich es mir selbst erklärt habe.
Was ist eigentlich eine KI? Das Wahrscheinlichkeits-Prinzip

Am einfachsten kann man es so beschreiben: Eine KI ist ein Wahrscheinlichkeitssystem.
Das klingt jetzt trocken, aber bleib kurz dabei. Stell dir vor, ich schreibe: "Ich esse gerne Pizza mit..." Was fällt dir als erstes ein? Käse? Salami? Genau. Du hast das nicht bewusst berechnet. Es kam einfach.
Eine KI macht im Grunde dasselbe, nur anders. Sie wurde mit Milliarden von Texten aus dem Internet, aus Büchern, aus Webseiten trainiert. Und in all diesen Texten hat sie gelernt, welche Wörter wie oft aufeinander folgen.
Wenn sie jetzt "Ich esse gerne Pizza mit..." liest, schaut sie quasi in diesen riesigen Erfahrungsschatz und fragt sich: Was kam in all diesen Texten am häufigsten nach diesem Satz? Käse vielleicht mit 65 Prozent. Salami mit 40 Prozent. Ananas mit 10 Prozent. Und dann wählt sie das, was statistisch am wahrscheinlichsten ist.
Das ist natürlich ein sehr vereinfachtes Beispiel. In Wirklichkeit erkennt eine KI auch Zusammenhänge zwischen Ideen. Sie lernt, dass ein Hund ein Tier ist, dass er bellen kann, dass er vier Beine hat. In diesem neuronalen Netzwerk, das ein bisschen wie ein Gehirn aufgebaut ist, werden diese Muster zwischen Wörtern und Konzepten immer wieder verknüpft und verfestigt.
Neuronale Netzwerke: Nicht so mysteriös, wie sie klingen
Der Begriff "neuronales Netzwerk" klingt nach Science-Fiction. Ist es aber nicht. Es ist einfach eine mathematische Struktur mit Millionen von Verbindungen zwischen Knotenpunkten, ähnlich wie Synapsen im Gehirn. Diese Verbindungen haben Gewichtungen, also Stärken. Je stärker eine Verbindung, desto wahrscheinlicher aktiviert sie die nächste.
Und genau diese Gewichtungen werden beim Training angepasst. Aber dazu gleich mehr.
Tokens: Was dein Prompt wirklich kostet

Bevor wir zum Training kommen, noch ein Konzept, das viele übersehen: Tokens.
Eine KI verarbeitet keinen Text so, wie wir ihn lesen. Sie zerlegt alles in kleine Einheiten, sogenannte Tokens. Ein Token kann ein ganzes Wort sein, ein Teil eines Wortes, oder auch nur ein einzelnes Satzzeichen.
Kleines Beispiel: "Ich liebe Pommes!" Das sind vier Tokens. "Ich", "liebe", "Pommes", und das Ausrufezeichen am Ende.
Spannend wird es bei seltenen Wörtern. Das Wort "erkläre" zum Beispiel kommt in Trainingsdaten nicht so oft vor. Also kann es sein, dass es in mehrere Tokens zerlegt wird, etwa "er", "kl" und "äre". Drei Tokens für ein einziges Wort.
Warum Deutsch mehr Tokens braucht als Englisch
Das hat direkte Auswirkungen auf dich, wenn du auf Deutsch arbeitest. Forschungen zeigen, dass Deutsch im Durchschnitt etwa 26 Prozent mehr Tokens braucht als Englisch für den gleichen Inhalt. Das liegt daran, dass Englisch viel häufiger in den Trainingsdaten vorkommt. Englische Wörter werden häufiger als komplette Tokens gespeichert. Deutsche Wörter, besonders die langen Komposita wie "Donaudampfschifffahrtsgesellschaft", werden dagegen in viele kleine Stücke zerlegt.
Was bedeutet das für dich? Zwei Dinge.
Erstens: Prompts auf Englisch sind für eine KI oft effizienter. Das Modell verarbeitet sie leichter, weil die Verbindungen zu ganzen Wörtern einfacher hergestellt werden können. Nicht immer, aber oft liefert der gleiche Prompt auf Englisch ein besseres Ergebnis als auf Deutsch.
Zweitens: Du zahlst bei API-Nutzung nach Tokens. Auf Deutsch zahlst du also mehr für denselben Inhalt.
Wie eine KI trainiert wird
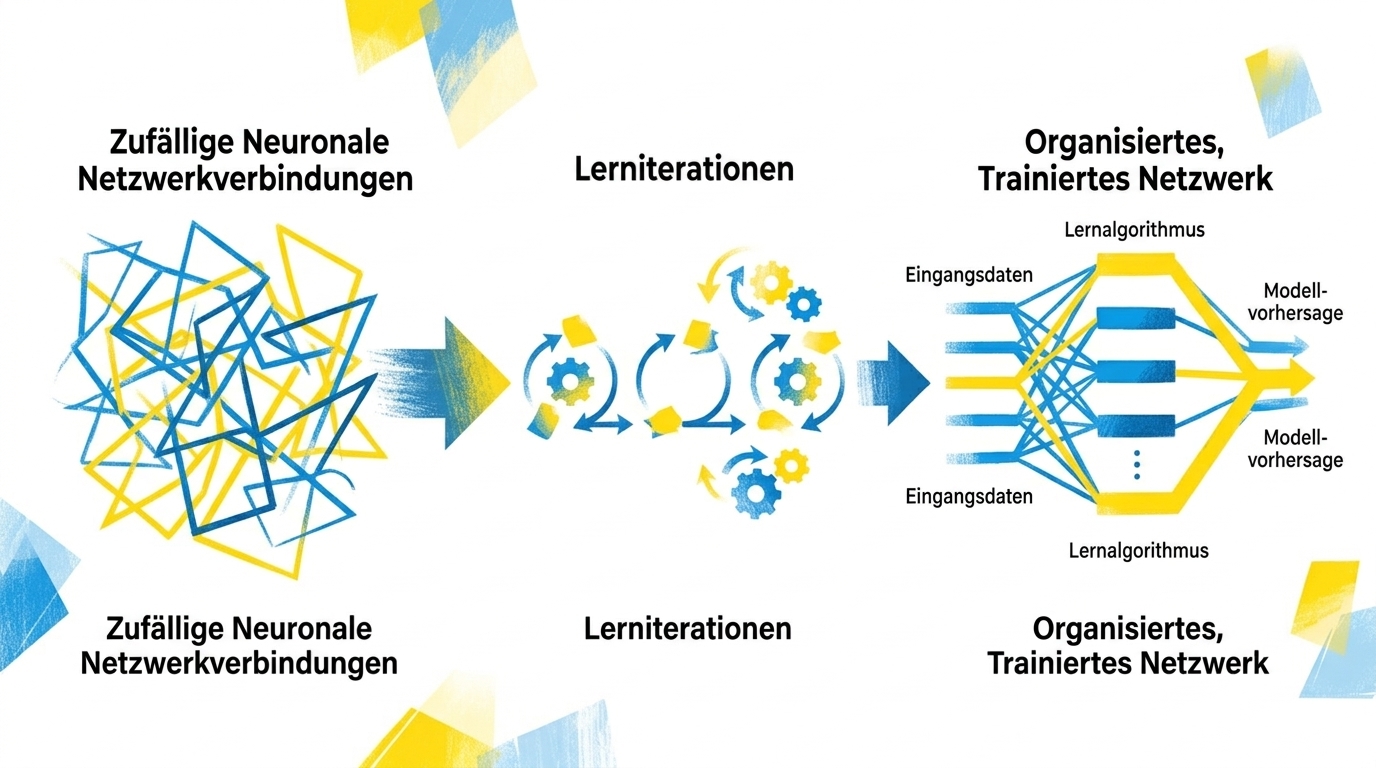
Jetzt zum eigentlich spannenden Teil. Wie wird aus einem Haufen Rechenoperationen ein System, das mit dir diskutieren kann?
Am Anfang ist eine KI buchstäblich bei null. Wie ein Neugeborenes. Das neuronale Netzwerk existiert zwar, mit all seinen Millionen Verbindungen, aber die sind völlig zufällig eingestellt. Es gibt keinen logischen Zusammenhang zwischen irgendwas. "Frühstück" und "Brötchen" haben keine stärkere Verbindung als "Frühstück" und "Auto".
Phase 1: Vorhersagen, Fehler, Anpassen
Dann beginnt das Training. Die KI liest Milliarden von Texten und macht ständig Vorhersagen. Was kommt nach diesem Wort? Was folgt auf diesen Satz?
Wenn im Text immer wieder Sätze stehen wie "zum Frühstück esse ich ein Brötchen", lernt das System nach einer Weile: nach Frühstück kommt oft Brötchen. Und wenn es falsch liegt, also wenn es "Auto" vorhersagt, werden die Gewichtungen im Netzwerk angepasst. Die Verbindung "Frühstück → Brötchen" wird stärker. Die Verbindung "Frühstück → Auto" wird schwächer.
Das passiert vollautomatisch durch Algorithmen. Keine menschliche Hand stellt da einzelne Gewichte ein. Das System vergleicht seine Vorhersagen mit dem, was im Text steht, und passt sich selbst an. Millionen mal, Milliarden mal, über Wochen und Monate.
Und mit der Zeit lernt die KI nicht nur einzelne Wortpaare, sondern komplexe Zusammenhänge. Dass Brötchen essbar sind. Dass man sie beim Bäcker kauft. Dass sie aus Mehl bestehen. Alles, was in diesen Texten über Brötchen stand, wird zu einem Teil des Modells.
Phase 2: Reinforcement Learning, der Feinschliff
Modelle wie Claude oder ChatGPT durchlaufen nach diesem ersten Training noch einen weiteren Schritt: Reinforcement Learning from Human Feedback, kurz RLHF.
Dabei bewerten Menschen, welche Antworten hilfreich sind, welche nützlich, welche problematisch. Diese Bewertungen fließen in weitere Trainingsrunden ein. Die KI lernt so nicht nur, Sprache zu verstehen, sondern auch, wie man sinnvoll mit Menschen kommuniziert.
Das ist übrigens auch der Grund, warum dein Daumen hoch oder Daumen runter bei ChatGPT nicht sinnlos ist. Diese Bewertungen werden gesammelt und fließen in zukünftige Trainingsrunden ein. Dein Feedback ist Teil eines kollektiven Lernprozesses.
Was dieses Training kostet
Nur kurz zur Einordnung: Das Training moderner KI-Modelle kostet Unsummen. Das Training von GPT-4 soll laut Schätzungen zwischen 63 und 100 Millionen Dollar gekostet haben, ohne die Gehälter der Forscher eingerechnet. Und das ist bereits von ein paar Jahren. Aktuelle Modelle sind teurer.
Das erklärt auch, warum nur wenige Unternehmen in der Welt überhaupt in der Lage sind, solche Systeme zu bauen.
KI vs. Mensch: Wo liegt der echte Unterschied?
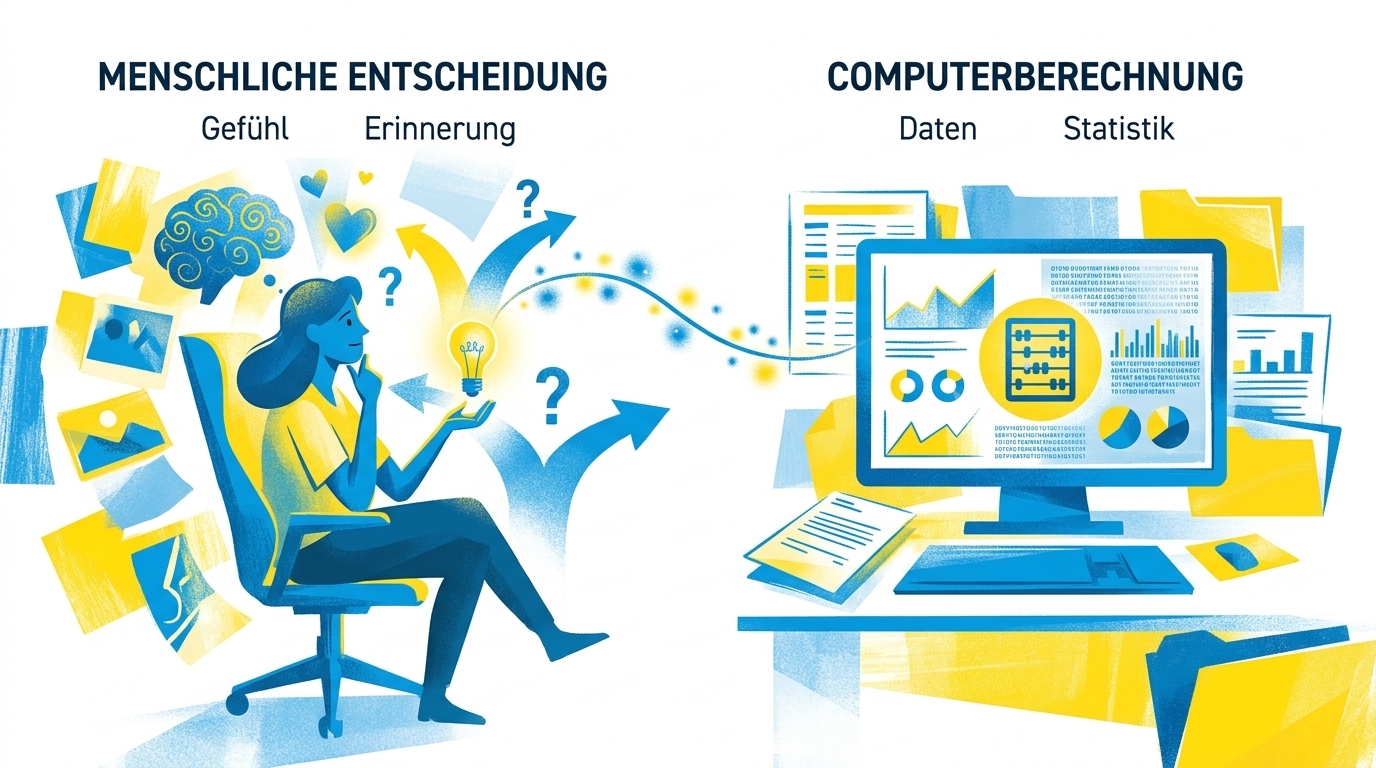
Eine Frage, die ich mir oft stelle: Was ist der fundamentale Unterschied zwischen dem, was eine KI macht, und dem, was wir machen?
Geh zurück zum Pizza-Beispiel. Wenn ich dich frage, was auf deine Pizza gehört, antwortest du vielleicht mit Ananas. Nicht weil das statistisch die häufigste Antwort ist, sondern weil du Ananas magst. Weil du eine Erinnerung daran hast. Ein Gefühl. Eine persönliche Geschichte.
Eine KI hat das nicht. Sie schaut in ihre Trainingsdaten und wählt das, was statistisch am wahrscheinlichsten ist. Käse. Weil Käse millionenfach in Pizza-Kontexten vorkam.
Menschen entscheiden aus Erlebnissen. KIs entscheiden aus Daten.
Das ist keine Schwäche der KI. Es ist einfach eine andere Art zu "denken". Und es hat praktische Konsequenzen: Eine KI wird immer Richtung Durchschnitt tendieren, wenn du ihr keinen klaren Kontext gibst. Wenn du willst, dass sie dein spezifisches Problem löst, musst du ihr auch deinen spezifischen Kontext geben.
Was passiert, wenn eine KI lernt, in der Welt zu handeln?
Das ist eine der interessantesten offenen Fragen. Würde eine KI, die echte Erfahrungen sammeln könnte, anfangen, anders zu entscheiden? Nicht mehr auf Basis statistischer Wahrscheinlichkeiten, sondern auf Basis dessen, was sie selbst erlebt hat?
Wir wissen es noch nicht. Aber es ist eine Frage, die KI-Forscher intensiv beschäftigt.
Was das alles für dich bedeutet
Du musst das alles nicht im Detail verstehen, um eine KI gut zu nutzen. Aber ein paar Dinge helfen.
Erstens: Gib der KI immer Kontext. Sie kann keine Gedanken lesen. Sie arbeitet mit dem, was du ihr gibst. Je spezifischer du bist, desto besser das Ergebnis.
Zweitens: Versteh, dass sie in Wahrscheinlichkeiten denkt. Wenn du willst, dass sie aus dem Durchschnitt ausbricht, musst du ihr sagen, wohin. Ein Rolle, ein Format, ein Beispiel.
Drittens: Prompts auf Englisch können effizienter sein, besonders bei komplexen Aufgaben. Nicht immer, aber es lohnt sich, es zu testen.
Und viertens: Eine KI ist nur so gut wie ihre Trainingsdaten. Sie weiß nichts über Ereignisse nach ihrem Trainingsabschnitt. Sie hat kein Spezialwissen über dein Unternehmen, deine Branche, deine Situation, außer du gibst es ihr.
Das sind die Grundlagen. Im nächsten Teil geht es darum, warum KIs manchmal einfach lügen, also was wirklich hinter Halluzinationen steckt, und was Forscher bei Anthropic in den Neuronen einer KI gefunden haben.